
Всем привет, меня зовут Евгений Мунин. Я Senior ML Engineer в Ad Tech в платформе ставок для рекламы и автор ТГ канала ML Advertising. По долгу службы приходится сталкиваться с пайплайнами данных, включая потоковые сервисы, и сегодня расскажу про один такой.
Давайте, представим, что мы разрабатываем рекомендательную систему для электронной коммерции маркетплейса. Пользователь заходит на его страницу, и в этот момент мы должны сделать рекомендацию товара, в предположении, что пользователь его купит. Мы можем обучить модель офлайн тому, понравится ли пользователю наша рекомендация или нет. Далее на проде на каждое событие входа пользователя дергаем нашу модель, передаем ей на вход данные о сессии пользователя, чтобы она сделала предсказание. Если логика маркетплейса и рекомендательной системы реализованы в одном и том же сервисе, то даже в случае неполадок на стороне предсказательной модели, данные о сессии пользователя никуда не теряются. Они остаются на сервере и мы их можем повторно переиспользовать. Все просто!

Теперь давайте предположим, что мы делаем все тоже самое, но для стороннего маркетплейса. Он общается с нами только HTTP запросами, и теперь в случае проблем на нашей стороне входные данные о сессии пользователя могут быть потеряны. Что же делать в этом случае?
Можно попробовать писать входные запросы в буферную SQL базу данных и в случае инцидента запрашивать пропущенные данные о сессии пользователя из нее. Но что делать если количество пользователей резко возросло (например в связи с праздниками и сезоном покупок)? Масштабировать SQL сервер — это задача достаточно муторная.

На помощь приходит Apache Kafka! Это платформа для потоковой передачи данных с открытым исходным кодом. Ее можно сделать независимой от нашего рекомендательного сервиса и сохранять входные данные в буфер, а главное делать это распределенно. Несмотря на то, что ее код написан на Java, существуют API, позволяющие использовать Python, Scala и другие языки. Мы можем представить Kafka как инструмент распределенной обработки входных данных и последующего их хранения. Пользователи могут читать эти данные и использовать их по назначению.
Прежде всего, давайте, поймем, из каких компонентов состоит Kafka, и как они между собой взаимодействуют.
Терминология Kafka
Итак, начнем с определений:
- Топик (Topic)
- Сообщение (Message)
- Партиция (Partition)
- Брокер (Broker)
- Продюсер (Producer)
- Консьюмер (Consumer)
Топик
Это сущность нашего набора данных, и мы можем рассматривать ее как контейнер, в котором хранятся события. Топик можно представить как журнал событий, в который мы можем делать запись в конец. Также мы можем настроить период хранения данных в топике для экономии места.
Сообщение
Сообщения представляют собой содержимое топика и состоят из ключа, значения, таймстампа и хедера. Ключи задаются, как правило, байтовым или строковым типом. Ключи могут служить идентификатором пользователя, устройства или транзакции в приложении. Значения могут быть представлены любым типом. Если для одного топика используется несколько машин, то сообщения могут быть распределены между ними по хешу ключа.
Логика распределенного хранения сообщений реализована с помощью партиций (о них мы расскажем ниже). При записи в партицию топика каждое новое сообщение получает свой монотонно возрастающий офсет (или смещение), который является 64-битным числом и назначается брокером. Офсеты уникальны внутри одной партиции и позволяют управлять порядком чтения сообщений. Например, мы можем сказать, чтобы сообщения читались только один раз, или наоборот мы можем позволить читать сообщения с одним и тем же офсет повторно, если не удалось это сделать ранее.

Брокер
Брокеры — это машины (или серверы), на которых запущена Kafka. Каждый брокер может размещать набор партиций и обрабатывать запросы на чтение и запись сообщений в этих партициях. Обычно на проде используется не один брокер а несколько, объедененных в кластер.
Партиция
Kafka сообщения внутри топика хранятся в партициях. Каждый топик может состоять из одной и более партиции. Они распределены между брокерами внутри одного кластера. Это необходимо для того, чтобы приложения-клиенты могли читать и писать сообщения распределено, т.е. с нескольких брокеров одновременно.
Номер партиции для сообщения выбирается исходя из его ключа. Сообщения с одинаковыми ключами всегда записываются в одну партицию. Если ключи пустые, партиции заполняются равномерно.

Продюсер
Приложения клиенты, взаимодействующие с Kafka, могут работать в двух режимах: записи и чтения сообщений. Продюсеры пишут сообщения в Kafka топики. При записи они передают адрес брокера, конфиги безопасности и содержимое сообщения.
Консьюмер
Консьюмеры — аналогично продюсерам, тоже приложения на стороне клиента. Они читают сообщения из Kafka топика.
Теперь, обратимся к вопросу, как мы можем обозначить сообщения прочитанные консьюмером, как обработанные? Для этого в Kafka существует механизм обработки (или коммита) офсетов. Ранее мы сказали, что во время чтения из партиции офсет, указывающий на положение сообщения в ней, должен не убывать. В это время консьюмер делает запрос брокеру для обновления текущего офсета, или другими словами, коммитить офсет. Брокер сохраняет эту информацию в своем собственном специальном топике под названием __consumer_offsets.
В Kafka также различают 2 вида семантики (или правил) чтения сообщений из топика
at-least-once(хотя бы один раз): семантика гарантирует, что все сообщения будут прочитаны консьюмером. В этом случае возможна ситуация дублирования сообщений. Эта семантика используется по умолчанию.at-most-once(не более одного раза): означает, что Kafka не будет повторно отправлять сообщения консьюмеру. Если консьюмер упал на обработке сообщения с офсетомn, который уже был закоммичен и сдвинут наn+1, сообщение будет утеряно.
Эффект распределенности в чтении из топика достигается за счет того что несколько консьюмеров могут быть объединены в группу (Consumer Group). Внутри одной группы сообщения уже поделены между консьюмерами за счет разделения на партиции. Каждая партиция обрабатывается одним консьюмером внутри группы, чтобы избежать повторной обработки. Часта ситуация, когда несколько групп консьюмеров могут читать из одного топика, поскольку после чтения сообщения не затираются.

Также стоит упомянуть о том, что на проде стараются не делать число консьюмеров большим числу партиций в топике. Предположим, нам требуется масштабировать консьюмер группу в связи с увеличением объема данных. Если мы добавим консьюмеры, при том, что все партиции уже назначены, то новые консьюмеры останутся незадействованы, и это не поможет нам увеличить пропускную способность сервиса. В первую очередь, мы должны увеличить количество партиций и уже после этого масштабировать консьюмер группу.
Сравнение с системами очередей
При первом взгляде на Kafka может сложится впечатление, что она аналогично классическим системам очередей таким как RabbitMQ или Amazon SQS. Но на самом деле это не так. Несмотря на то, что системы очередей также состоят из аналогичных базовых компонент: сервера с хранилищем сообщений, продюсеров, консьюмеров, их главным отличием от Kafka является следующее:
- В системах очередей в после прочтения консьюмером сообщения, оно удаляется навсегда. В Kafka сообщение не удаляется брокером и может хранится в топике по усмотрению пользователя.
- Благодаря этому одно и тоже сообщение может быть прочитано сколь угодно раз разными группами консьюмеров.
Применение Kafka в проде
Теперь, давайте, вернемся к нашему примеру с рекомендательной системой. Мы решили использовать Кафку для буферного хранения входных запросов о сессии пользователя.
Мы можем поднять сервис (назовем его Streaming service), независимый от нашей рекомендательной системы, который будет общаться со сторонним маркетплейсом. Также создадим два Kafka топика
- Для входных данных для рекомендательной модели
- Для выходных предсказаний
В момент входа пользователя на страницу маркетплейса наш Streaming service принимает HTTP запрос и Kafka продюсер может записать сообщение о входе пользователя и данные о нем в топик. Далее мы можем прочитать это сообщение и запустить предсказание модели. После мы записываем предсказания в топик. Streaming service их читает и передает HTTP ответ на маркетплейс.

Если нам нужно масштабировать сервис, то достаточно увеличить количество партиций в топиках и коньсюмеров в группах.
Kafka Consumer на Python
Теперь, давайте, напишем небольшой игрушечный пример. В нем мы создадим Kafka кластер через Confluent Cloud. Хотя это можно сделать и руками на локальной машине или, например, напрямую в AWS, для простоты решения мы воспользуемся готовым функционалом Confluent Cloud. Далее создадим Kafka топик, напишем свой консьюмер на Python, используя библиотеку confluent_kafka, запустим его и проверим записываемые сообщения.
Для начала нужно создать учетную запись на Confluent Cloud. Затем настраиваем Kafka-кластер. Здесь мы можем выбрать провайдера, у которого Confluent Cloud будет арендовать сервера для кластера и установит на них Kafka. Можно выбрать среди AWS, Google Cloud и Azure. Назовем наш кластер cluster_0.
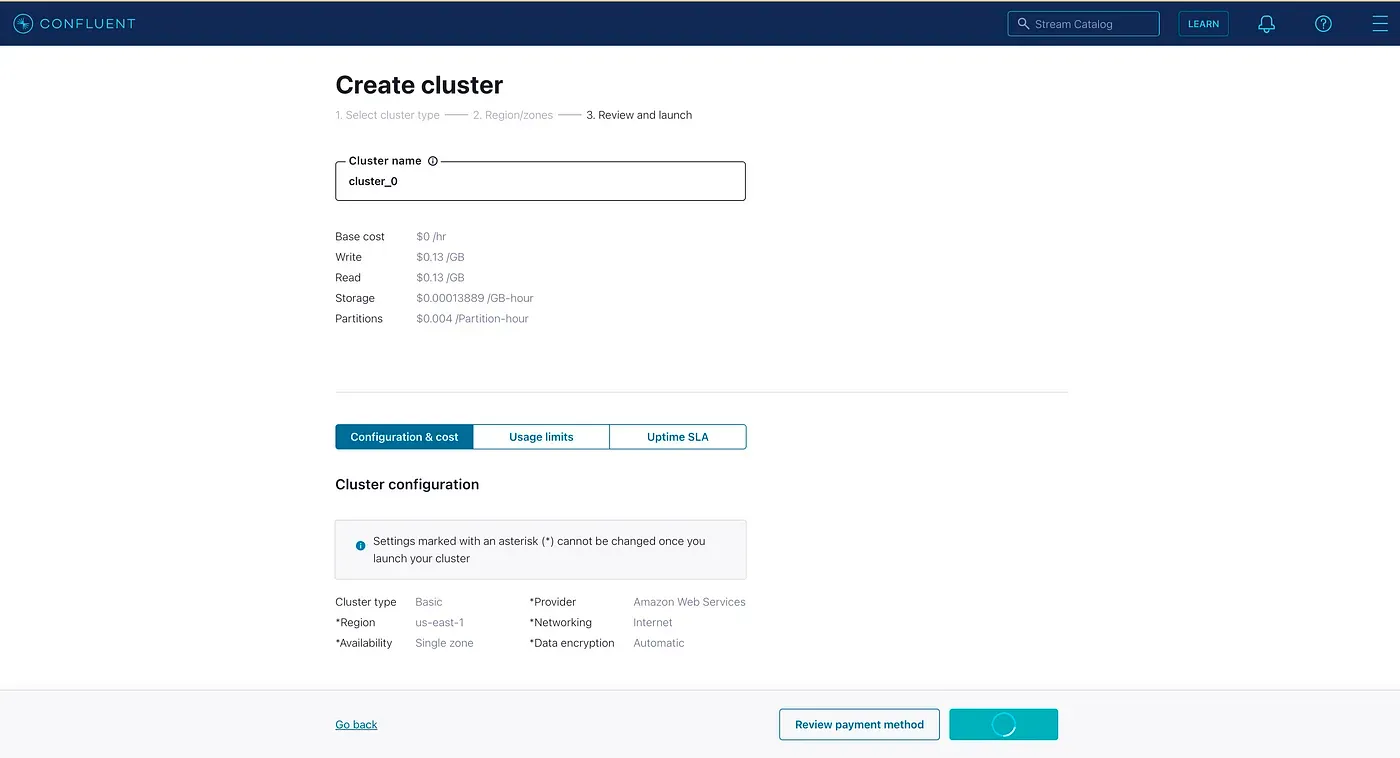
После того, как кластер запущен, переходим на вкладку topics и создаем топик Kafka. Назовем его topic_0 . Мы также можем выставить число партиций в топики, которое по умолчанию равно 6.
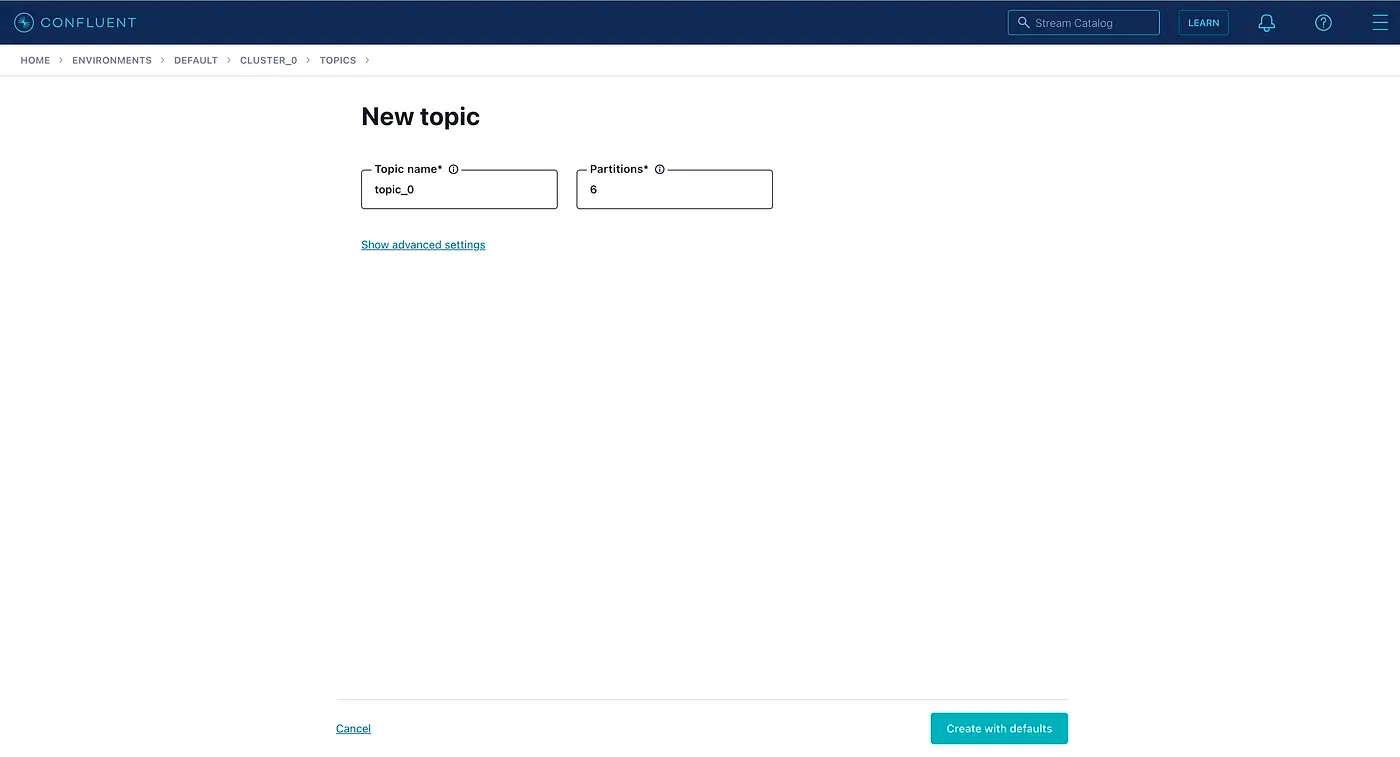
Теперь, когда топик создан, нам нужно установить Confluent CLI и подключиться к нашему кластеру, войдя в аккаунт Confluent Cloud. Для этого можно использовать следующие команды (для Mac):
brew install --cask confluent-cli
confluent loginПодсоединившись, проверяем environment ID и выбираем соответствующее значение, доступное в Confluent Cloud (скорее всего оно будет единственным).
confluent environment list
confluent environment use <env-ID>Поскольку мы уже создали Kafka кластер cluster_0, он должен отобразиться в списке.
confluent kafka cluster list
confluent kafka cluster use <cluster-ID>Для связи с кластером создаем API Key и Secret Key.
confluent api-key create --resource <cluster-ID>
confluent api-key use <API-Key> --resource <cluster-ID>Теперь, когда связь с кластером установлена, мы можем увидеть в списке ранее созданный топик topic_0.
confluent kafka topic list
Далее создадим консьюмер. Под словом консьюмер мы понимаем консьюмер группу. Для начала, напишем конфиг файл config.ini, где определим имя сервера, на котором запущен Kafka кластер, протокол безопасности и ранее созданные нами ключи доступа.
[default]
bootstrap.servers=pkc-n00kk.us-east-1.aws.confluent.cloud:9092
security.protocol=SASL_SSL
sasl.mechanisms=PLAIN
sasl.username=<API-Key>
sasl.password=<Secret-Key>
[consumer]
group.id=python_group_1
auto.offset.reset=earliestЧтобы узнать bootstrap адрес сервера запустим следующую команду и скопируем значения из поля Endpoint SASL_SSL. Bootstrap сервер является первой точкой контакта для приложения клиента (в нашем случае консьюмера) при подключении к кластеру Kafka. Консьюмер подключается по указанному нами URL к bootstrap серверу и запрашивает метаданные о других доступных серверах (брокерах) в кластере. Как только консьюмер получил данные о доступных брокерах, он может установить соединение с ними напрямую и начать читать сообщения.
confluent kafka cluster describe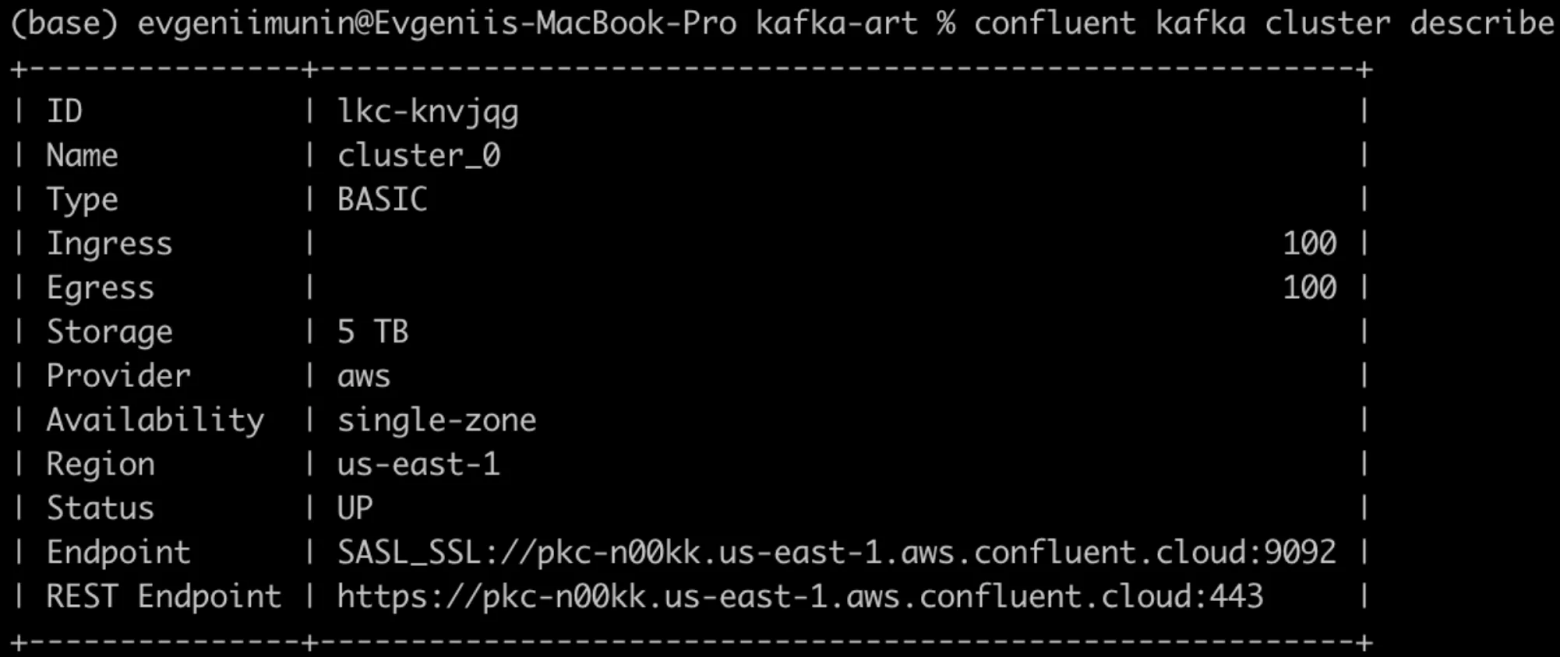
Далее напишем консьюмер в скрипте consumer.py . В нем мы распарсим файл конфига, создадим инстанс Consumer , с его помощью прочитаем сообщения из топика и выведем содержимое в консоль. По умолчанию у консьюмера включен авто-коммит офсетов. Это значит, что после прочтения каждого сообщения офсет обновляется автоматически, и нам не нужно на каждом новом сообщении коммитить офсет руками.
#!/usr/bin/env python
from argparse import ArgumentParser, FileType
from configparser import ConfigParser
from confluent_kafka import Consumer
if __name__ == '__main__':
# parse the command line
# parse config file and pass to new consumer instance
parser = ArgumentParser()
parser.add_argument('config_file', type=FileType('r'))
args = parser.parse_args()
# parse configuration
config_parser = ConfigParser()
config_parser.read_file(args.config_file)
config = dict(config_parser['default'])
config.update(config_parser['consumer'])
# create consumer instance
consumer = Consumer(config)
# subscribe to consumer topic
topic = "topic_0"
consumer.subscribe([topic])
# poll for new messages from kafka and print them
# pull messages from topic and react, print status or kafka msg
try:
while True:
msg = consumer.poll(1.0)
if msg is None:
print("Waiting...")
elif msg.error():
print("ERROR: %s".format(msg.error()))
else:
# Extract the (optional) key and value, and print.
print("Consumed event from topic {topic}: key = {key:12} value = {value:12}".format(topic=msg.topic(), key=msg.key().decode('utf-8'), value=msg.value().decode('utf-8')))
except KeyboardInterrupt:
pass
finally:
consumer.close()Запустим скрипт с помощью следующих команд:
chmod u+x consumer.py
./consumer.py config.iniПосле запуска, консьюмер перейдет в режим ожидания входящих сообщений. Чтобы их создать и записать в топик запустим продюсер из второго терминала. При этом сообщения записываем в формате key:value, разделяя их двоеточием : .
confluent kafka topic produce topic_0 --parse-key
1:message 1
2:message 2
3:message 3
4:message 4
5:message 5
6:message 6
7:message 7
8:message 8После записи сообщений мы их увидим в первом терминале. Это значит, что они были успешно прочитаны консьюмером.
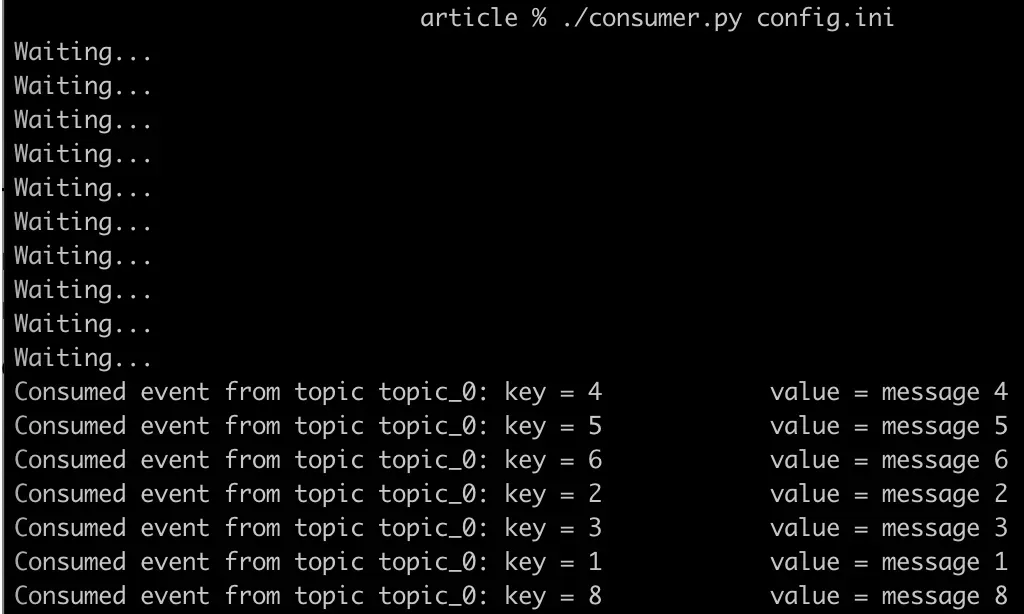
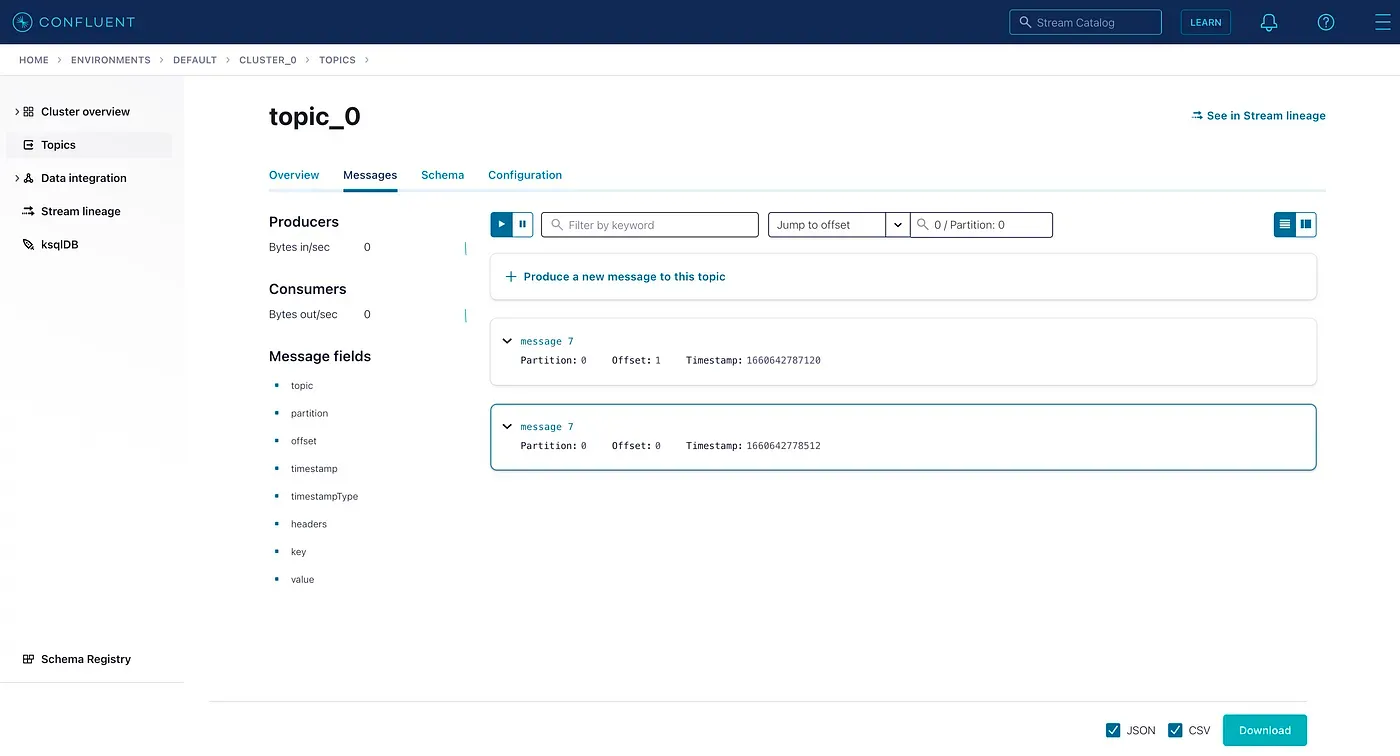
Мы также можем отобразить сообщения в графическом интерфейсе Confluent Cloud. Здесь, например, мы можем видеть, что сообщение 7 доступно с офсетом 0 в партиции 0.
Мысли и заключения
Могу сказать, что из личного опыта работы на проде Kafka помогает сильно улучшить отказоустойчивость сервисов с ML моделями. При наличии Kafka топика в роли буфера для хранения данных на вход в модель гораздо проще устранять случаи инцидентов связанных, например,
- с падением виртуальных машин EC2, на которых запущены модели,
- с проблемами с загрузкой весов модели,
- с несоответствием версий библиотек после их обновления.
В подобных случаях входные данные от третье сторонних сервисов не теряются и остаются записаны в сохранности в топике. А после устранения инцидента можно просто обработать необработанные сообщения.
Но Kafka не всегда является подходящим решением на все случаи жизни и имеет недостатки:
- При неправильном выборе семантики обработки сообщений консьюмером, они могут быть потеряны. Например, мы выбираем порядок обработки
at-most-onceи читаем первое и второе сообщение со смещением 1 и 2 соответственно. При этом второе сообщение обработалось успешно, а первое нет. Но поскольку, консьюмер уже закоммитил офсет на второе сообщение, к первому мы уже не вернемся, и оно будет утеряно. В этом случае, решением будет изменить семантику обработки сообщений наat-least-once, но дублированные сообщения будет сложнее отлаживать. - Использование Кафки усложняет архитектуру нашего сервиса. Ее сложнее тестировать, отлаживать и поддерживать. Трудности могут возникнуть, например:
- с распределением сообщений по партициям
- или с записью и вычитыванием сообщений в топики.
- Поэтому имеет смысл использовать Кафку в относительно нагруженных сервисах, например, крупных маркетплейсах или аукционах реального времени, с количеством запросов от 1…10M в час. Если таких требований на сервис не накладывается, то можно обойтись более простыми решениями, записывая данные, например, в SQL или храня в кеше в Redis.
Итак, в этой статье мы познакомились с базовыми функциями и определениями Kafka, смогли поднять кластер в Confluent Cloud и запустить консьюмер. Буду рад вашей обратной связи!
Спасибо всем, кто дочитал до конца!