
В этой статье я:
- расскажу об интересных возможностях Zabbix
- поделюсь кейсами их использования и примерами настроек
- сравню Zabbix и Grafana и расскажу, как мы применяем их в тандеме
Информация будет полезна продуктовым командам, которые используют только Grafana для визуализации сервисных метрик и алертинга, но хотят масштабировать и развивать свой мониторинг.
Что такое Zabbix
Zabbix — это широко известная open-source система для отслеживания состояния IT-инфраструктуры, приложений и сервисов. Позиционируется как комплексное решение для мониторинга и управления инцидентами.
Итак, фишки Zabbix
- Хранение данных
- Зависимости алертов
- Запуск автоматических действий
- Синтетический мониторинг
- Автообнаружение
- Интеграция с системами аналитики
1 – Хранение данных
Zabbix собирает и хранит метрики в своей БД, чем не может похвастаться та же Grafana. Это позволяет лучше отслеживать тренды, обращаться к историческим данным, не нагружать лишний раз источники объемными запросами, если нужно получить информацию за большой период.
Сама база данных создается в процессе установки Zabbix-сервера. Поддерживаются следующие СУБД: MySQL, PostgreSQL, Oralce и SQLite.
Для корпоративных сред рекомендуется сразу настроить бэкапы, housekeeping (очистка исторических данных) и мониторинг самой БД.
2 – Зависимости алертов
Классическая история: инфраструктурный сбой, влияющий сразу на несколько сервисов, порождает спам уведомлений.
Например, если возникают проблемы с доступностью БД, то вместе с алертом по Базе данных срабатывают уведомления о недоступности всех связанных с ней сервисов, отвлекая от главного. А по сути нужно знать только одно — упала база.
Или другая ситуация — вы хотите настроить приоритеты алертов так, чтобы они учитывали уровень ошибок в сервисе.
Для таких случаев в Zabbix есть функционал настройки зависимостей, который помогает не засорять эфир и сохранять эмоциональное здоровье.
Пример настройки:
В настройках триггера переходим во вкладку Dependencies, жмем Add и добавляем один или несколько триггеров, от которых должен зависеть настраиваемый триггер.
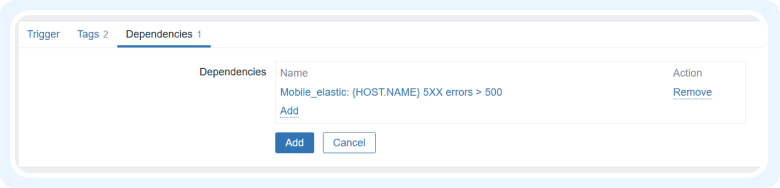
Перед срабатыванием нашего триггера, Zabbix проверит зависимости, и если триггер {HOST.NAME} 5XX errors > 500 тоже находится в статусе Problem, то состояние нашего триггера не будет изменено.
3 – Запуск автоматических действий
В Zabbix можно не просто мониторить метрики, но и запускать автоматизации после срабатывания триггеров, что существенно повышает оперативность и снижает время простоя продукта. Для этого есть функционал Trigger actions.
В общем случае он используется для отправки уведомлений, но его можно настроить и для других задач, таких как создание тикета в Jira, перезапуск службы, откат релиза или запуск других скриптов.
Пример настройки:
В качестве примера покажу настройку Trigger action для создания тикета в Jira и отправки уведомления в Telegram.
1) Создаем каналы доставки в Administration > Media types. Шаблоны тут.
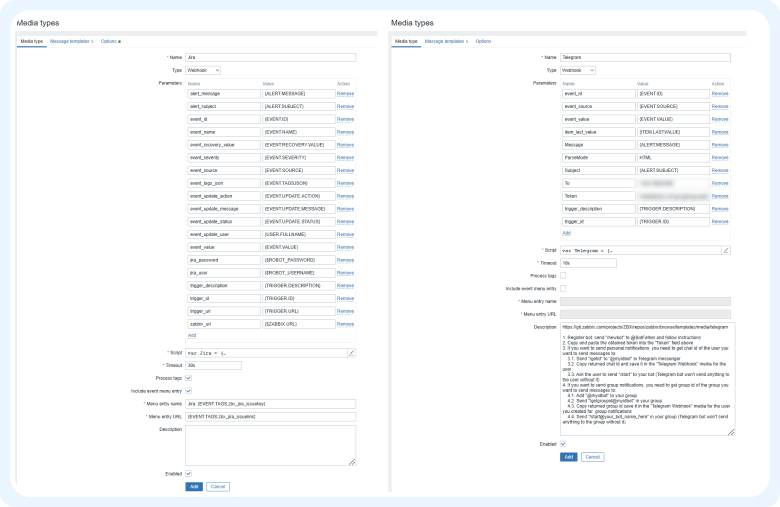
2) Переходим к настройке действия в Configuration > Actions > Trigger actions.
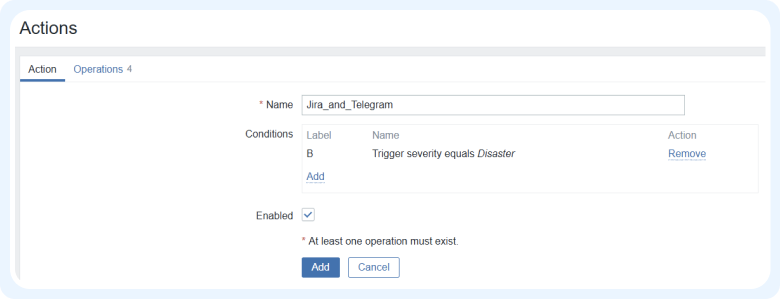
На вкладке Action даем название действию и добавляем условия, для которых оно будет применяться. Это может быть тег, хост, уровень триггера и т. д.
На вкладке Operations добавляем последовательность операций с типом Send message. С помощью настроек шагов регулируем задержку между первой и второй операцией. Это нужно для того, чтобы к моменту отправки уведомления ссылка на тикет в Jira была получена и передана в Telegram.
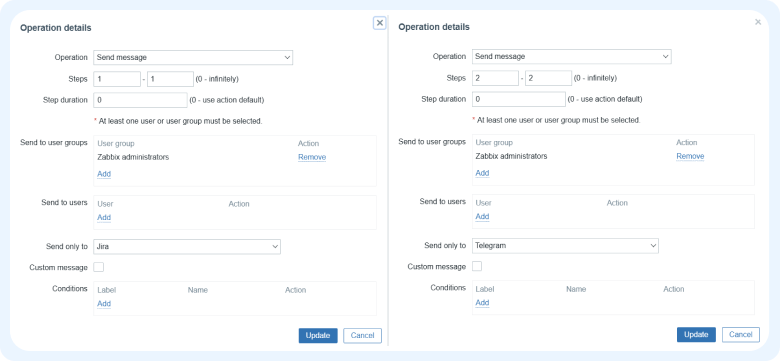
Сохраняем итоговые настройки.
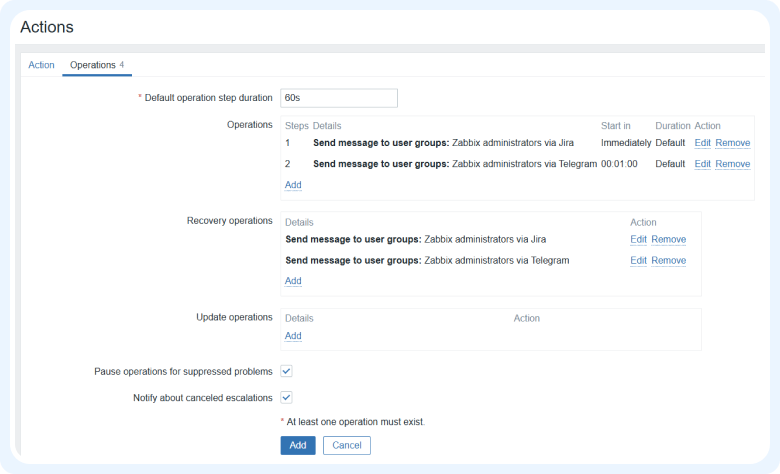
Теперь, когда сработает триггер уровня Disaster, Zabbix инициирует создание тикета в Jira и отправит уведомление в Telegram со ссылкой на него.
Если потребуется запускать какой-то скрипт, то логика настройки аналогичная, просто нужно сперва добавить скрипт через Administration > Scripts, а после выбрать его в качестве типа операции при создании действия триггера.
4 – Синтетический мониторинг
Еще одна замечательная функция называется Web-сценарии. Благодаря ей Zabbix может по заданным правилам отправлять HTTP-запросы на нужный ресурс и отслеживать скорость, статус и тело ответа.
Когда это может быть полезно:
- Если есть зависимость от сторонних сервисов и нужно дополнительно контролировать их состояние.
- Если хочется проверять не только код ответа, но и то, что его тело содержит ожидаемые поля.
- Если есть страницы или эндпоинты, на которых мало трафика. В таких случаях отслеживать уровень ошибок может быть затруднительно, и активный мониторинг сообщит, если что-то идет не так. Например, у нас есть лендинг, на который в день заходит меньше 10 пользователей. Настраивать алерт на 2 ошибки в день по логам нелогично и неэффективно. Проще проверять доступность лендинга, делая к нему запрос раз в 5 минут.
Пример настройки:
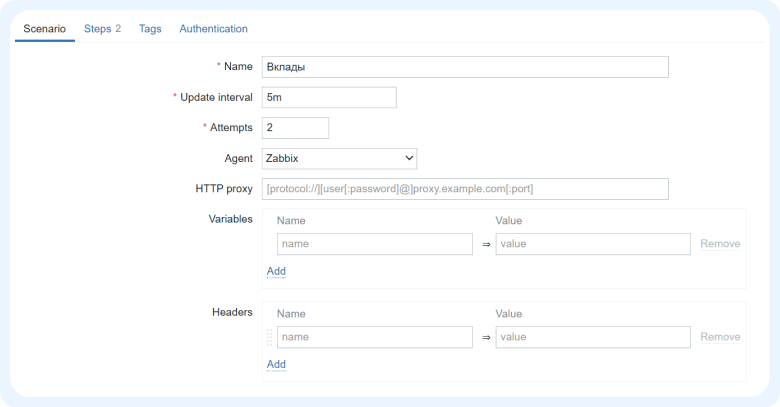
1) Идем в Configuration > Hosts >. В строке выбранного хоста нажимаем Web > Create web scenario.
2) Указываем имя, интервал и количество попыток выполнения сценария.
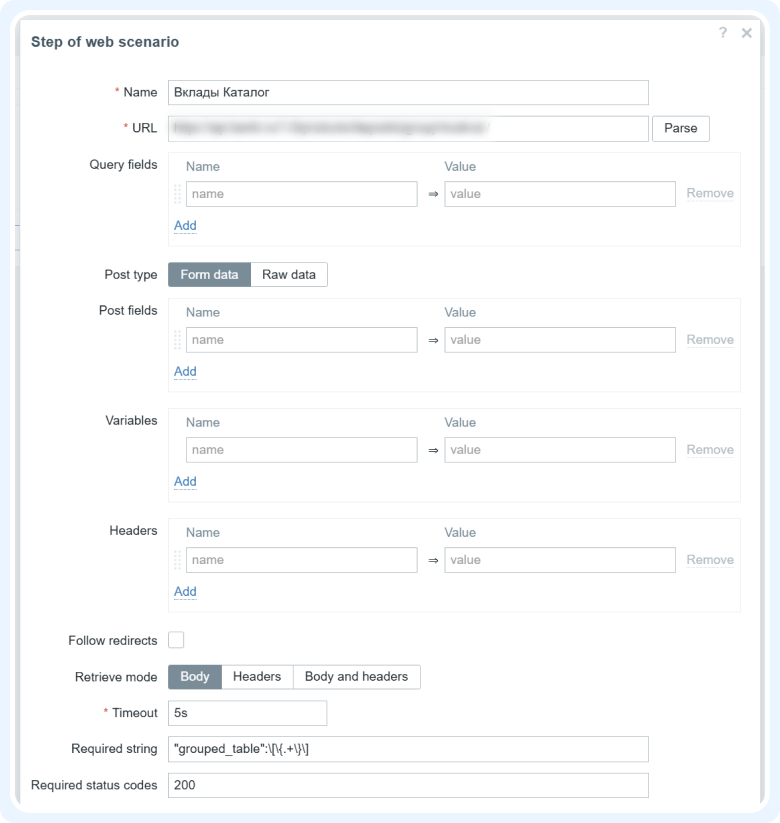
3) Переходим на вкладку Steps и добавляем один или несколько шагов. Они определяют, какие HTTP-запросы вызывать и какой код ответа или строку из тела ответа ожидать.
Тут важно обратить внимание, что шаги идут последовательно и успех сценария зависит от успеха всех входящих в него шагов.

4) Когда мы определили шаги и создали сценарий, идем в Triggers и настраиваем условия срабатывания. Например:Expression: sum(/web/web.test.fail[Вклады],#3)>=3 — выражение примет значение true, когда за 3 проверки будет провалено 3 и более шага.
5 – Автообнаружение
Представьте себе ситуацию: в вашей инфраструктуре постоянно добавляются серверы, запускаются сервисы, и каждый раз вы вручную настраиваете для них базовый мониторинг. Это утомительно, а если вы что-то забудете — рискуете упустить неисправность.
С помощью правил автообнаружения Zabbix можно настроить систему так, чтобы она сама находила новые ресурсы, добавляла их в мониторинг и сразу применяла нужные шаблоны. Так вам не придется делать ручные настройки, следить за актуальностью мониторинга и переживать, что вы о чем-то забудете.
Этот функционал может быть особенно полезен при внедрении заббикса в уже существующую инфраструктуру — так не придется заводить все элементы данных и триггеры вручную.
Пример настройки:
В качестве примера я взял настройку автообнаружения новых веб-сервисов через выполнение HTTP-запроса в services-registry нашей компании.
1) Идем в Configuration > Templates и создаем новый шаблон. Затем привязываем его к хосту, в привязке к которому будут автоматически создаваться элементы данных и триггеры.
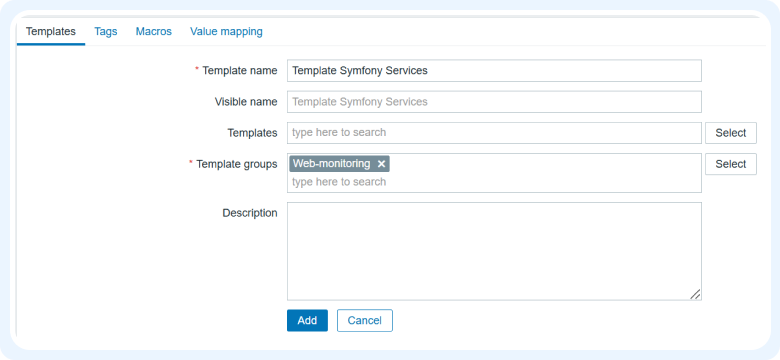
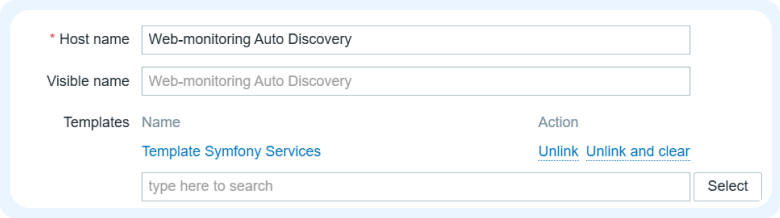
2) Далее создаем связанный с ним item, через который мы будем получать и обновлять список сервисов. В зависимости от тела ответа настраиваем предпроцессинг. Его можно настроить как на данном этапе, так и в самих правилах автообнаружения.
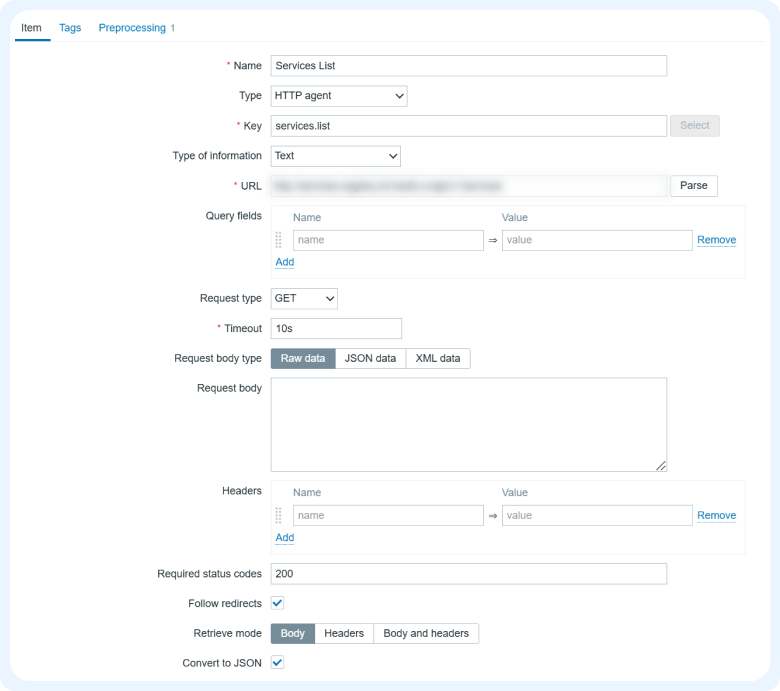
3) Теперь переходим в Discovery rules и создаем правило.
В поле Type выбираем зависимый элемент, а в Master item ссылаемся на элемент, через который получаем список сервисов.
Тут у кого-то может возникнуть вопрос: а зачем мы сделали отдельный элемент данных на предыдущем шаге и теперь ссылаетесь на него, если можно делать запрос прямо из правила, выбрав соответствующий Type?
Ответ: оба варианта рабочие, а выбор зависит от потребностей. Если планируете использовать данные в нескольких правилах, то будет проще контролировать и поддерживать их получение через отдельный элемент, а затем переиспользовать их разными правилами.
Устанавливаем значение Keep lost resources period. Эта функция позволяет в течение выбранного периода сохранять элементы и триггеры по сервисам, которые перестали обнаруживаться — например, были удалены из реестра.
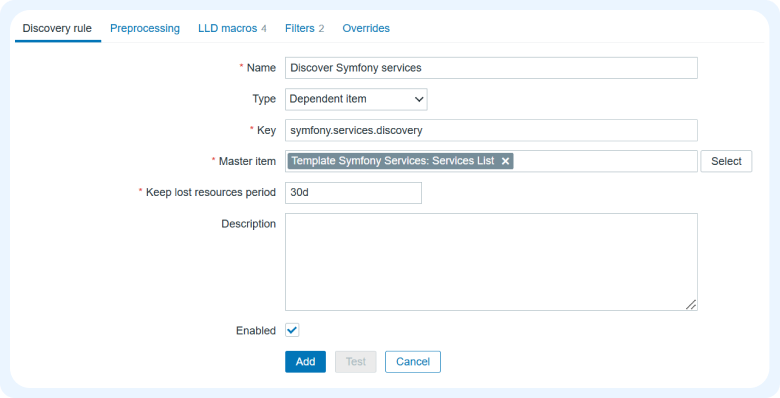
Создаем нужные переменные с помощью LLD макросов, чтобы затем использовать их при генерации элементов данных и триггеров.
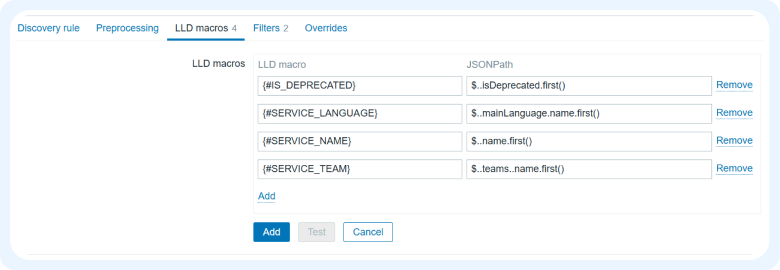
4) Осталось создать Item prototypes и Trigger prototypes с использованием макросов.
Например,
Name: {#SERVICE_NAME} количество ошибок уровня CRITICAL
и так далее.
Что мы получаем в итоге:
- Элементы данных и триггеры создаются автоматически на основе полученного списка сервисов.
- Заббикс автоматически актуализирует их, если список меняется.
- Внося изменения в прототипы, мы можем централизованно менять сразу N-ое количество объектов.
6 – Интеграция с системами аналитики
Если вы используете такие сервисы, как AppMetrica, Яндекс.Метрика или Google Analytics, то данные из них могут быть полезны для усиления мониторинга продуктовых метрик. Например, количество пользователей, переходы, события и т. д.
Пример настройки:
Рассмотрим настройку сбора данных через API AppMetrica:
1) Добавление внешнего приложения.
Чтобы создать приложение для работы с данными сервисов Яндекса, переходим по ссылке: https://oauth.yandex.ru/client/new/
Выбираем Веб-сервисы, в Redirect URI пишем https://oauth.yandex.ru/verification_code, в поле “Доступ к данным” выбираем доступы к статистике сервиса.
После этого завершаем создание приложения и попадаем в его карточку:
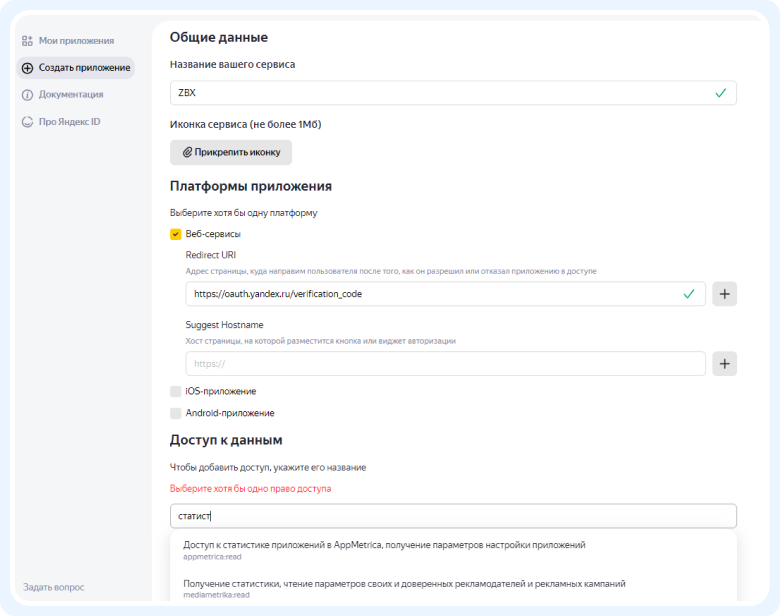
2) Далее нам нужно взять из карточки значение ClientID (идентификатор приложения) и подставить в ссылку https://oauth.yandex.ru/authorize?response_type=token&client_id=[client_id] вместо [client_id].
Переходим по ссылке и видим запрос на доступ к данным, которые мы выбрали при создании приложения. Подтверждаем его и получаем oauth-токен, с помощью которого будем забирать данные по API.
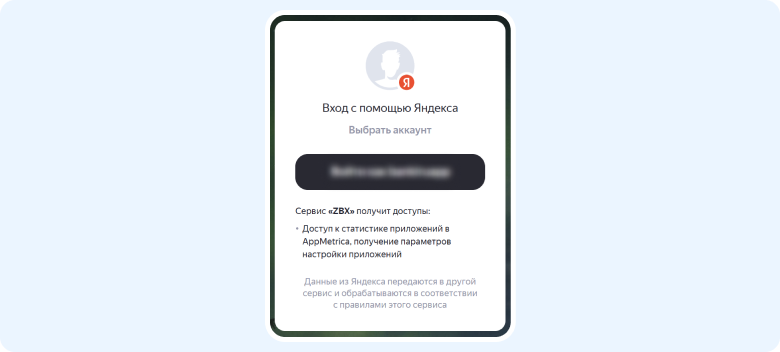
3) Теперь мы можем перейти в Zabbix и создать элемент данных. Будем отправлять запросы к API напрямую из Zabbix с помощью HTTP-agent и сразу же парсить полученный ответ.
Данные для формирования запроса можно взять прямо из интерфейса AppMetrica. Для этого формируем нужный отчет, после чего в настройках экспорта копируем API-запрос таблицы.
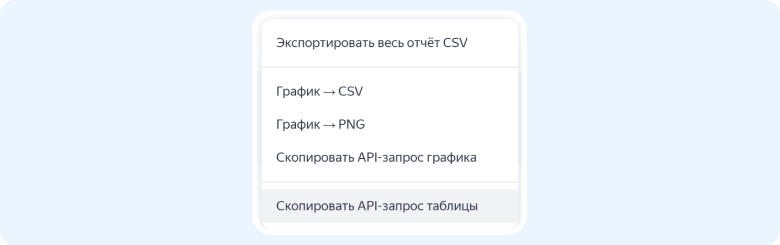
Вставляем его в элемент данных, жмем Parse, чтобы разложить query-параметры.
Даты можно заменить на переменные, например, чтобы ежедневно получать данные за вчерашний день.
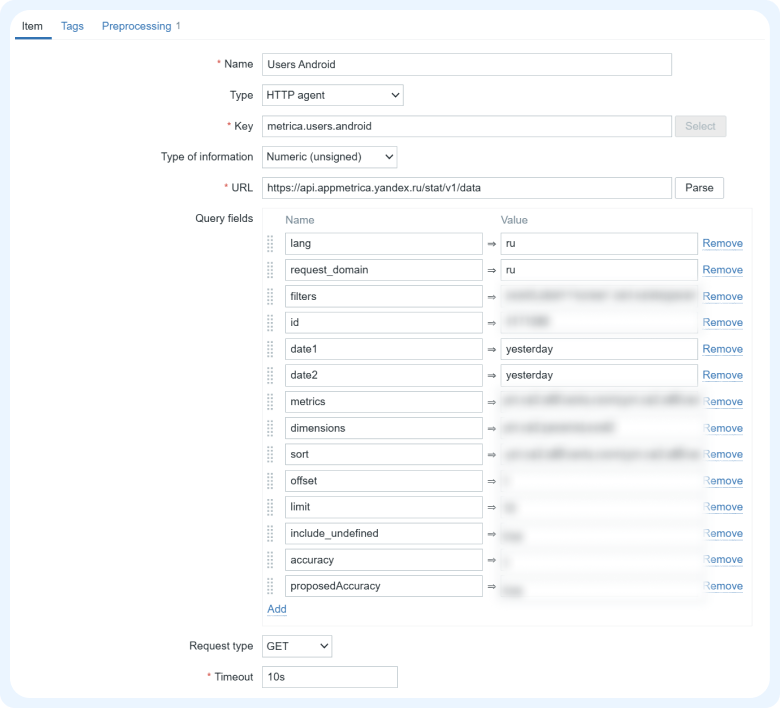
Прописываем обязательные заголовки Content-Type и Authorization (куда мы как раз и вставляем полученный ранее токен в формате OAuth [token]):

После этого остается только настроить парсинг значений из полученного ответа, например, через JSONPath.
Zabbix и Grafana
Grafana — это одна из популярнейших систем для визуализации данных. Многие компании используют её для построения технических и продуктовых дашбордов. При этом Grafana не хранит данные, а функционал работы с событиями рассчитан на простые сценарии использования.
Давайте сравним эти 2 системы:
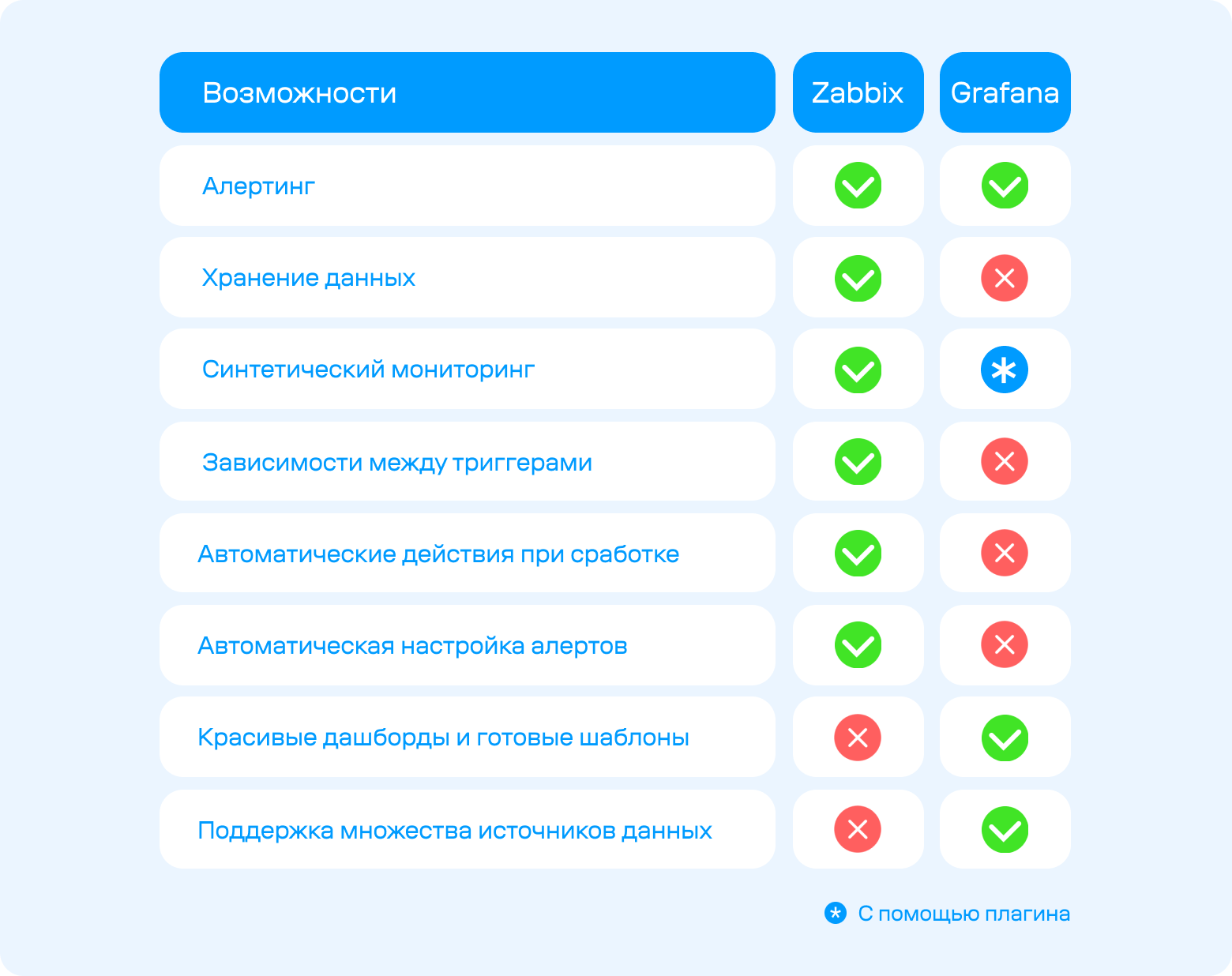
То есть, Zabbix — гибкий в плане настроек мониторинга, а Grafana позволяет строить наглядные дашборды и красивые графики. Эти системы отлично интегрируются и дополняют друг друга.
Для достижения лучшего эффекта наша команда использует их в связке: вся логика по сбору данных, алертингу и действиям реализована в Zabbix, который подключен в Grafana в качестве источника информации. Собранные данные выводятся в красивые дашборды и доступны для всем заинтересованным лицам.
В заключение хотелось бы добавить, что нет хороших и плохих инструментов. Каждый создан под свои задачи и специфику. Используйте их с умом, настраивайте чуткий мониторинг и предоставляйте пользователям надежные сервисы.